
What do you do with content and URLs that you don’t want showing up in Google’s SERPs? If you’re a content marketer, you’ve probably heard three common code tools come up in these kinds of conversations:
- 301 redirects
- Noindex (Usually “noindex, follow”)
- Rel=”canonical”
Each of these tools is useful, especially if you’re trying to clean up your blog, but there are some important differences to keep in mind when you’re considering using them. In this video, we’ll get a high-level view of what each of these tools is for, and how to put them to good use.

Video Transcript
Hi everyone, I’m Jeffrey. And today we’re going to talk about 301 redirects, un-indexed pages and that rel=canonical tag. Now these are tools that content marketers and SEOs use, generally, when they’re dealing with content that they don’t want to show up in search engines (the way regular content would). They are not interchangeable, but they tend to come up in the same conversations. So, right now, we’re going to look at the differences between them and what they’re all useful for. Let’s jump in.
We’ll start with 301 redirects.
What is a 301 redirect?
Now, a 301 redirect just means that the content on a URL has been permanently moved to another URL.
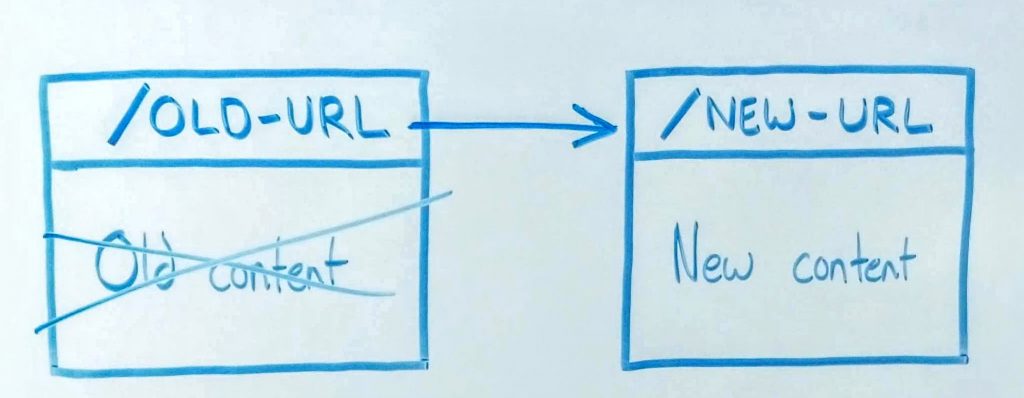
So, the way a 301 redirect works is, you have an old URL with old content. Once you set up a 301 redirect, then you tell browsers and search engines that everything that at this URL, should be moved to a new URL. It’s a redirect. This means that anyone who types in that old URL, will just be pushed right to that new URL.
Now what does that mean about the content that was at the old URL? Well, unless you move it somewhere else, then that’s not going to get found. So, that means that for a 301 redirect, when you put that into place, it’s really useful for a handful of really common content marketing activities. (Here’s a refresher on how content marketing works if you want to brush up on those activities!)
301 redirects are great for:
1. Merging redundant content
If you’re merging redundant content, then a 301 redirect works great because, you’re taking a bunch of old pages, and you’re saying, everything that was at these old URLs, we’re now going to have living at this new URL. So, any sort of link that someone’s following to that old page, takes them right to the new one. It’s really, really effective for merging old content.
Note: If you’ve been running a B2B blog for a while, this is a great way to build authoritative cornerstone content out of old posts—a key part of a good B2B SEO strategy.
2. Purging obsolete content
It’s also really good for purging content, and preserving those links. So, let’s say you have a bunch of blog posts that aren’t really useful anymore, but they gathered some links overtime. If you’ve been blogging for a long time, then you probably have a lot of posts like this. If you have posts that you really just want to get rid of, but they have inbound links, then a 301 redirect works really well. That way, when someone follows a link to your website, they have someplace to land. Now of course, you want to make sure that anytime you put one of those 301 redirects in place, that you’re sending them someplace that makes sense.
3. Updating URLs
Thirdly, they’re really good for cleaning and updating URLs. A lot of people start blogging, and they have these long strings of URLs, because their content management system turns the titles of their blog posts into URLs. And oftentimes, content marketers want to go back through those blog posts and tighten up those URLs into something that’s easier to remember and shorter and easier to type. Well, 301 redirects work really for that. You just take the old page or the content on that old URL, move it to a new URL and set up a 301 redirect, and you’re good.
De-indexing pages

Now let’s talk about un-indexed pages. For a lot of marketers, you’re going to have content that’s very, very useful to you but not really useful to the people who are using search engines. A lot of this content, you’ll find at the bottom of your sales funnel. Or maybe it’s just content for people who have already purchased and are already inside. For that sort of content, de-indexing your pages works really, really well.
This is really useful for content marketers in a variety of ways.
De-indexing pages is great for:
1. Hiding content that’s unhelpful to searchers
One is, it’s great to just hide content that unhelpful for search. Just get it out of the way. Because, what you’re doing is you’re saying that people can read that content on the de-indexed page, but they won’t find it in the search engine results pages. You’re essentially telling Google by de-indexing your page, “Yes this page exists. You can still crawl it, it’s not invisible. But, don’t surface this when people are Googling for content, because it’s not for people to find via search engine.”
2. Avoiding self-competition
And, that helps you by avoiding competing with yourself on those search terms. This way, Google’s algorithms don’t need to go through your site and say, “Alright, you have five different pages on this topic. Which one of these pages is really the most authoritative one on this topic?” You take all of that out of the equation by just de-indexing the pages that shouldn’t even be in the running for someone who’s searching on Google.
3. Hiding low-engagement pages
Thirdly, this is great for hiding low engagement pages. There are some pages on your site that people don’t spend a lot of time on, that don’t get a lot of traffic, and if Google sees a great deal of pages on your site that aren’t getting engagement. Then, that’s not really that great for you, doesn’t send good signals about your site as a whole. And so it’s often good to de-index those pages.
What is rel=”canonical”?
Third one of these that we’ll look at: the rel=”canonical”. Now, oftentimes marketers will be creating a bunch of pages that are, from a content standpoint, nearly identical. It’s duplicate content. But, when you have landing pages that are for specific audiences or maybe very, very slight variations in which case, it makes sense to have a separate page but, the content is still pretty much the same.
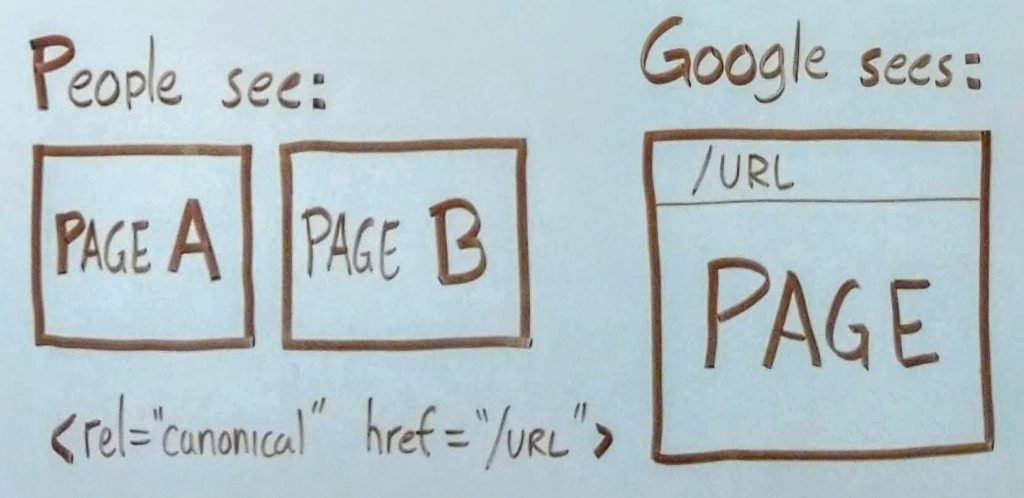
Then it’s really helpful to use this tag. Because, what you’re doing is you’re allowing people to see various pages, various versions of the same content. But, when you put in that rel=canonical tag and then, designate one URL that’s canonical, it’s the base URL, if you will.
That tells Google they only need to see this one page. So Google doesn’t see a ton of duplicate content on your site when you’re using this tag. You’re saying, “These pages are for people, but Google, just pay attention to this one page.” It sort of merges all this duplicate content together into one page for search engines to look at. And that’s really helpful on a few fronts.
Rel=”canonical” is great for:
1. Hiding duplicate content
Again, Google doesn’t really like duplicate content. It’s getting smarter and smarter at figuring out what that canonical page should be. But, you don’t want to leave that in Google’s hands when you can designate your own.
It’s also really great for URLs with parameters. Some people’s content management systems will throw in parameters at the ends of URLs that also get indexed. And so, I’ve seen some companies that have multiple duplicates of a certain piece of content, that get indexed. And it’s because they don’t have a single canonical URL set for those pages. This is generally something that you see when a URL contains a question mark and then, say, site search queries, product categories, and stuff like that.
A rel=canonical can be a good way of designating, there’s only one page where this is supposed to be found in search engines.
2. Reposting and syndication
There are a lot of instances in which, people write a blog post and then, that post gets shared on another website. And then, that re-post can sometimes outrank the original author’s version of the post. And that doesn’t feel so good.
Well, it’s helpful to use the rel=canonical tag because you’re telling Google that the re-posted page is really one and the same with that canonical page. So it tells Google, “This is the original. This is the official version of this page to be found in search.”
Wrapping up
So, you can see, these are very different. You use 301 to move content from one URL to another. You use noindex to say, “Keep this up, this is still really valuable content, but don’t show it in the search engine results pages.” And then, rel=canonical is for duplicate content. It allows you to show people your content in various experiences, but you still only give the search engines one authoritative page to consider canonical.
That’s how these three tools work and what makes them different for each other. And also, why they’re valuable tools for any content marketer.
